GRAPHHITS.R
Description
This R script takes the output from the blast.pl script, a hash file containing query names and their respective chromosome numbers ( queryIndex),
a hash file containing hit names and their respective chromosome
numbers ( hitIndex), and a hash file containing the coordinates of the intron/exon
boundaries ( IntEx). The script outputs one PDF file per target
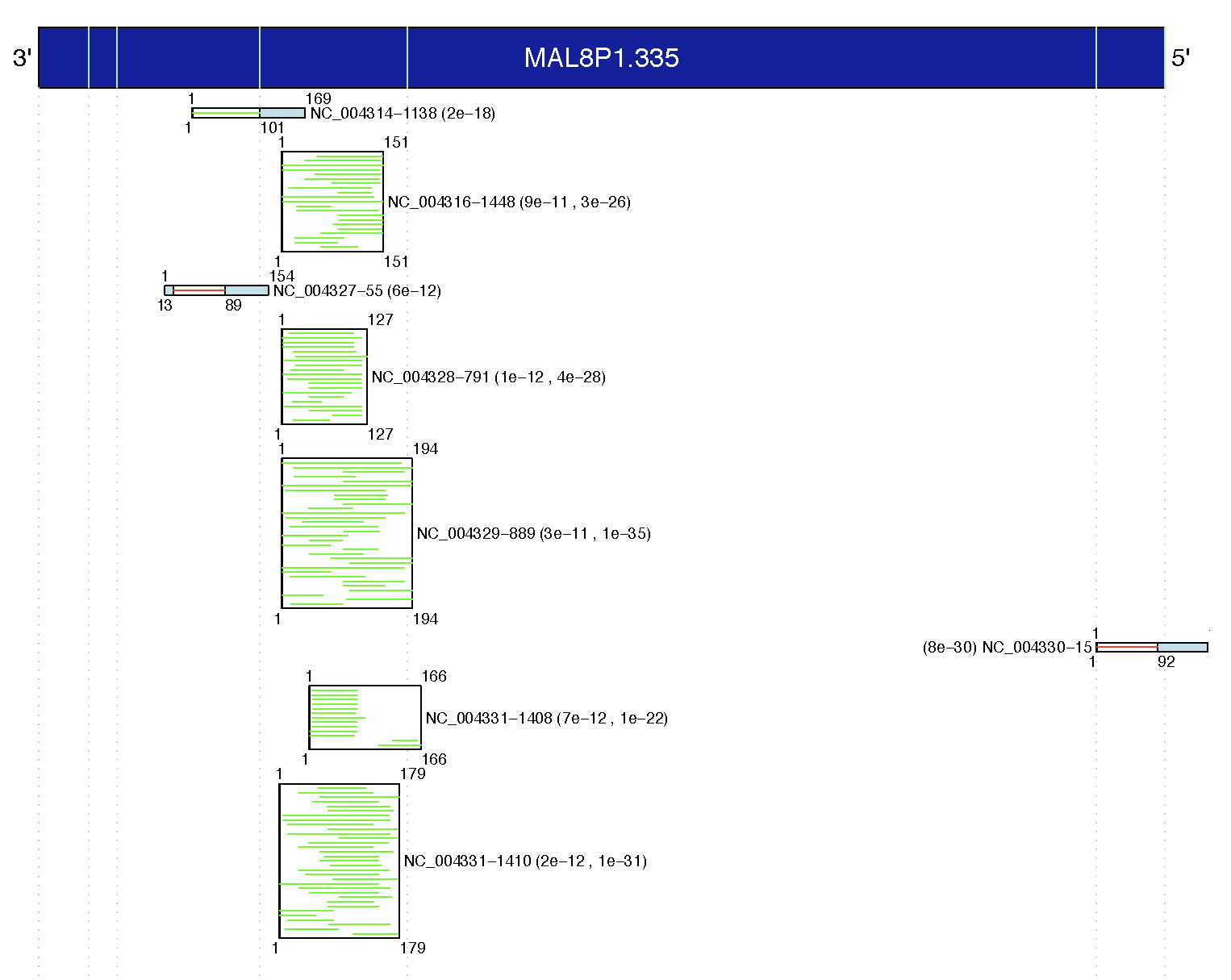
sequence. Each PDF file contains a diagram which shows all hits
from the list of query sequences that have matches against the target
with a significance level at or below the e-value passed to blast.pl.
Arguments
- out.txt (Table with BLAST hit information)
- queryIndex (Hash of subject sequences)
- hitIndex (Hash of target sequences)
- intEx (Hash of intron/exon boundaries)
*These files must all be in the same directory as the R script.
- outDir (directory where the pdfs are saved. Initially set to "pdfs/", but can be changed by editing the top of the R script)
Notes
**IMPORTANT**
Before this script can be run, you must ensure that there is a sub-directory named "pdfs". The script creates PDF files
and places them there. If no such directory is created the
following error (or something similar) will be generated:
Error in pdf(paste(outDir, targetName, ".pdf", sep = ""), width = pageWidth, :
unable to start device pdf
Usage:
The R scripts are all made so that they can be sourced into R. From an R prompt type:
> source("graphHits.R")
Output:
One PDF file per target sequence is created in the sub-directory "pdfs". Each filename has the structure TARGETNAME.pdf.
|