Research Overview
Statistical Methods for Air Pollution Exposures
 My
current focus is on developing statistical methods for
understanding the health effects of ambient air pollution. In
the United States and around the world, millions of people are
exposed to dirty air, much of which is generated by human
activity. Estimating the health effects of ambient air
pollution is an important problem in public health, but is
hampered by the need to identify small health risks in the
presence of much noise. This and other challenges can only be
addressed by developing state-of-the-art statistical models and
applying them to very large datasets.
My
current focus is on developing statistical methods for
understanding the health effects of ambient air pollution. In
the United States and around the world, millions of people are
exposed to dirty air, much of which is generated by human
activity. Estimating the health effects of ambient air
pollution is an important problem in public health, but is
hampered by the need to identify small health risks in the
presence of much noise. This and other challenges can only be
addressed by developing state-of-the-art statistical models and
applying them to very large datasets.
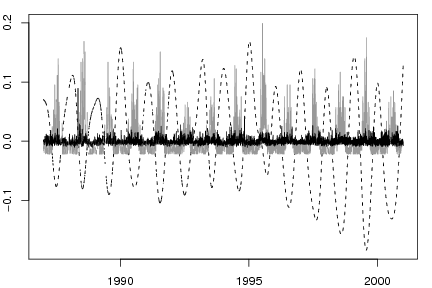
The picture to the right illustrates the inherent problem of estimating the health risks of ambient air pollution. In a model for predicting daily mortality, we might include three factors: (1) season, dashed black line, (2) temperature, the gray solid line, and (3) air pollution, the solid black line. For predicting daily mortality, season and temperature have large signals and contribute to a large part of the variation. Air polution, on the other hand, has a relatively small signal and is buried amongst the other two.
The challenge is to develop statistical methods for detecting this faint air pollution signal in a sea of much stronger signals as well as noise. To do this we need to use sophisticated statistical models and apply them to large, national level, datasets.
Assessing the Health Effects of Climate Change
Climate change is anticipated to affect human health largely by changing the distribution of known risk factors such as extreme heat episodes, floods, droughts, air pollution and aero-allergens, and vector- and rodent-borne diseases. In particular, an expected increase in the frequency, intensity, and severity of extreme heat episodes will likely have a profound impact on the public’s health. Designing interventions and mitigation strategies to protect public health requires first developing a clear understanding of how extreme heat episodes differentially affect vulnerable populations with respect to mortality and morbidity. We are interested in developing statistical methods for estimating the various health effects of climate change. We are currently focusing on developing statistical approaches to estimating the mortality/morbidity effects of heat waves and developing statistical models for describing malaria incidence in southern Africa.
Computational Methods for Reproducible Research
Replication of scientific findings by independent investigators using independent methods, data, instruments, and laboratories is the standard method by which scientific findings are verified and is how knowledge is accumulated. However, in instances where full replication of study findings is not possible because of either time or expense, we need a minimum standard that can capture some of the benefits of replication. This kind of situation is common with large epidemiologic studies, particularly ones that are used for making policy decisions.
 One such minimum standard is what I and
others call reproducibility, an idea that is usually
traced back to Jon Claerbout at Stanford University. Claerbout
claimed that the results of a paper, be they figures or tables,
are not scholarship, but rather they are the advertising of the
scholarship. The real scholarship is embodied in the data and
methods underlying the figures and tables.
One such minimum standard is what I and
others call reproducibility, an idea that is usually
traced back to Jon Claerbout at Stanford University. Claerbout
claimed that the results of a paper, be they figures or tables,
are not scholarship, but rather they are the advertising of the
scholarship. The real scholarship is embodied in the data and
methods underlying the figures and tables.
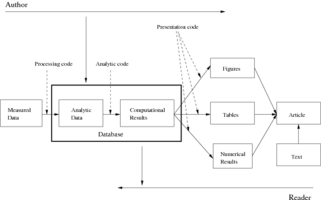
I define a study to be reproducible if (1) the analytic data are made available; (2) the statistical methods are fully described and computer code is made available; (3) documentation for both data and methods made available; and (b) standard methods of distribution are employed. Reproducibility is critical for studies where the likelihood for full replication within a relevant time window is very low.
Currently, we lack siginificant infrastructure for conducting and distributing reproducible research. We need servers, websites, software tools, protocols, and standards for exchanging data, methods, and other information. Right now I am working on developing the Reproducible Research Archive as a public resource for making generic statistical analyses available to others. I am focusing on developing it for R software right now but I hope to extend it to other systems after gaining some experience.
Funding
Our work has been funded by- National Institute of Environmental Health Sciences
- US Environmental Protection Agency
- Health Effects Institute
- Johns Hopkins Malaria Institute
- National Institute of Allergy and Infectious Diseases